Елизавета Никулина рассказала студентам-гуманитариям о цифровых технологиях в лингвистике
В докладе на Гуманитарном форуме она привела пример совместной работы лингвистов и разработчиков нейросетей над цифровым сервисом оценки удобочитаемости.

11-13 апреля в Политехе проходила III Всероссийская молодежная научно-практическая конференция «Гуманитарный форум в Политехническом».
Цель конференции – вовлечение студентов и аспирантов в активный процесс формирования современных междисциплинарных знаний и компетенций, развитие актуальных социо-гуманитарных исследований и тем научного дискурса, обмен научными достижениями и активное взаимодействие участников в рамках научных и практико-ориентированных мероприятий на базе Гуманитарного института СПбПУ.
Конференция была адресована студентам и аспирантам высших учебных заведений, интересующимся вопросами социо-гуманитарной проблематики, а также молодым специалистам, желающим представить на обсуждение свои проекты.
Специалист Лаборатории ПСПОД ПИШ СПбПУ Елизавета Никулина рассказала о проекте по созданию интерактивного цифрового инструмента для оценки удобочитаемости и визуального восприятия новостей на веб-сайтах вузов. Проект был реализован в 2022 году. Его инициатором была Высшая школа лингводидактики и перевода Гуманитарного института СПбПУ. Программную разработку вела Лаборатория «Промышленные системы потоковой обработки данных» ПИШ СПбПУ.
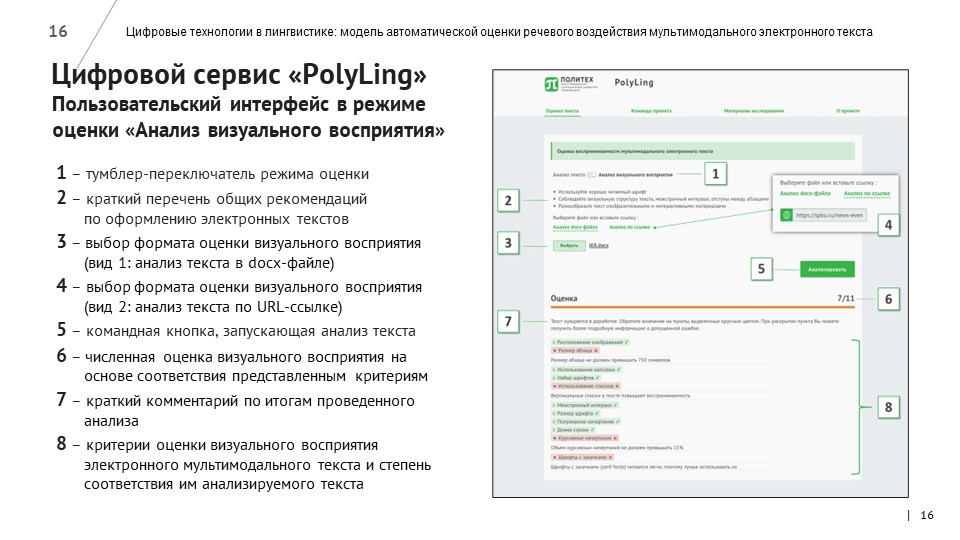
Результатом совместной работы стал цифровой сервис PolyLing, основанный на нейросетевой модели автоматической оценки речевого воздействия мультимодального электронного текста.
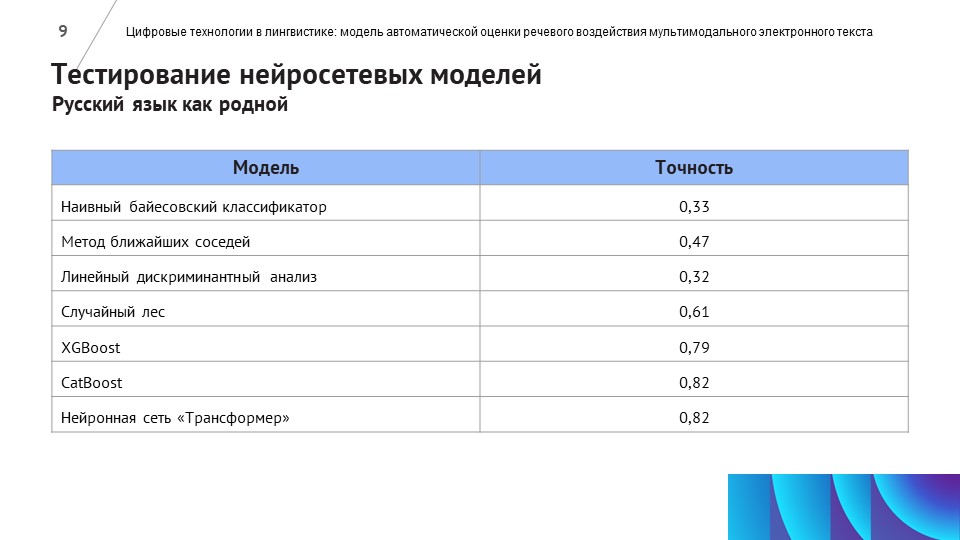
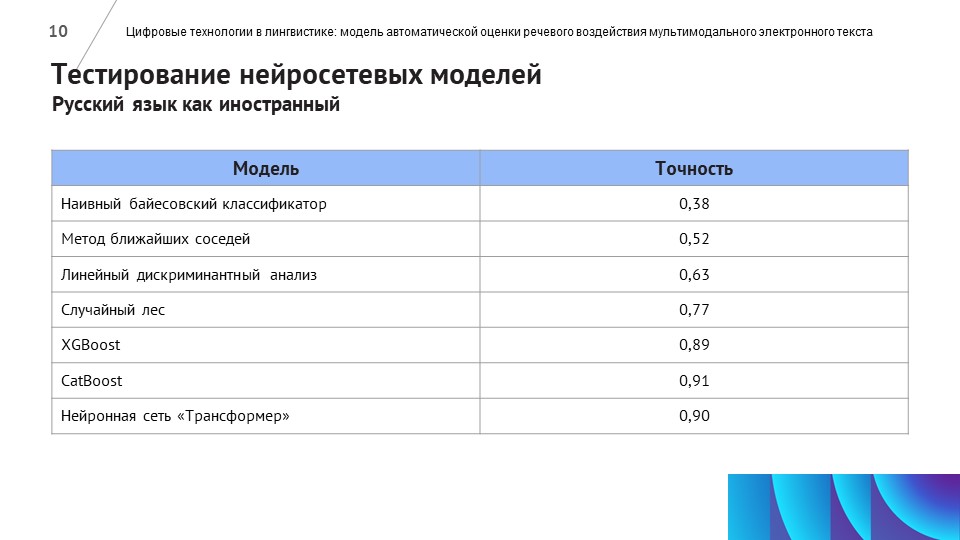
Для обучения нейросети потребовались компетенции специалистов по русскому языку, компьютерных лингвистов и программистов – разработчиков нейросетей.
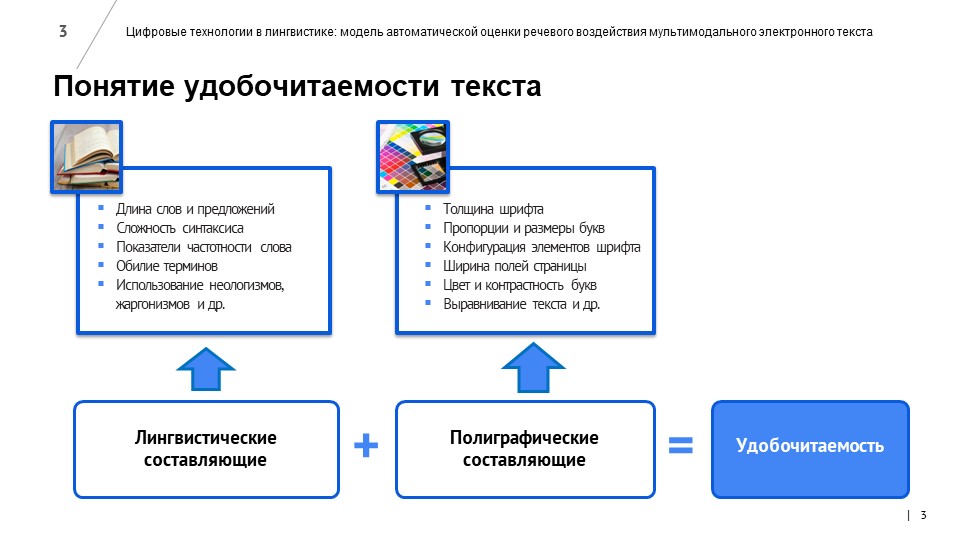
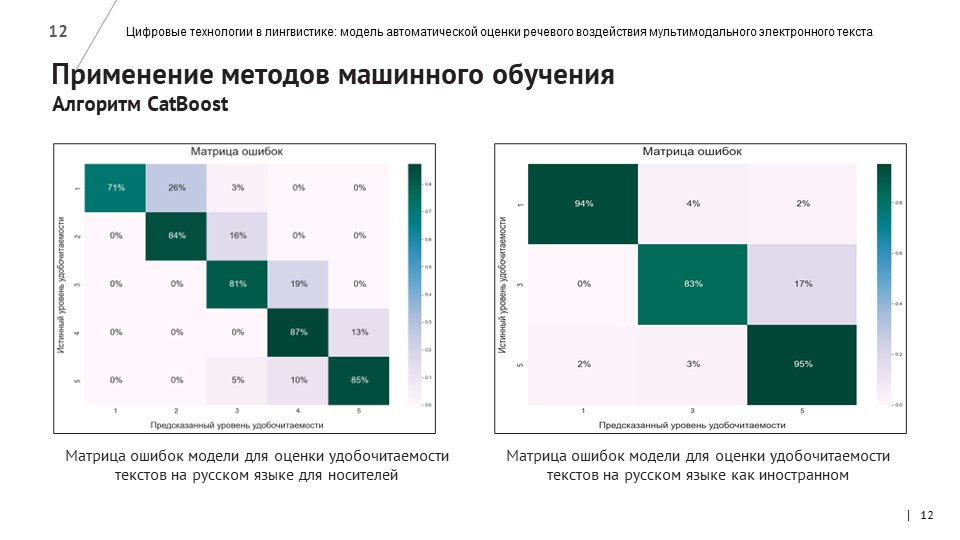
Лингвисты собрали и проанализировали самые важные метрики оценки качества текста для носителей русского языка и иностранцев, владеющих русским. Новости оценивались по лингвистическому и визуальному критериям – с точки зрения качества текста и верстки контента на веб-странице.
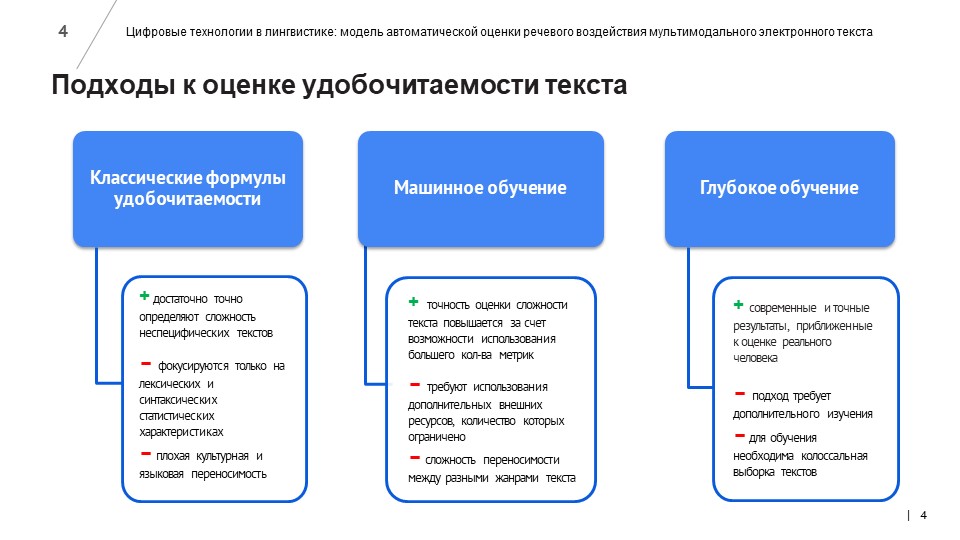
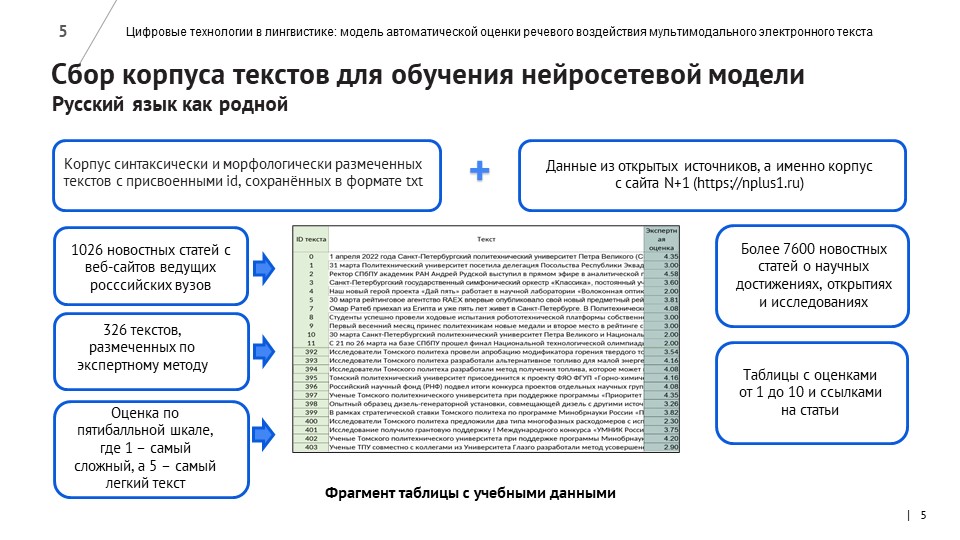
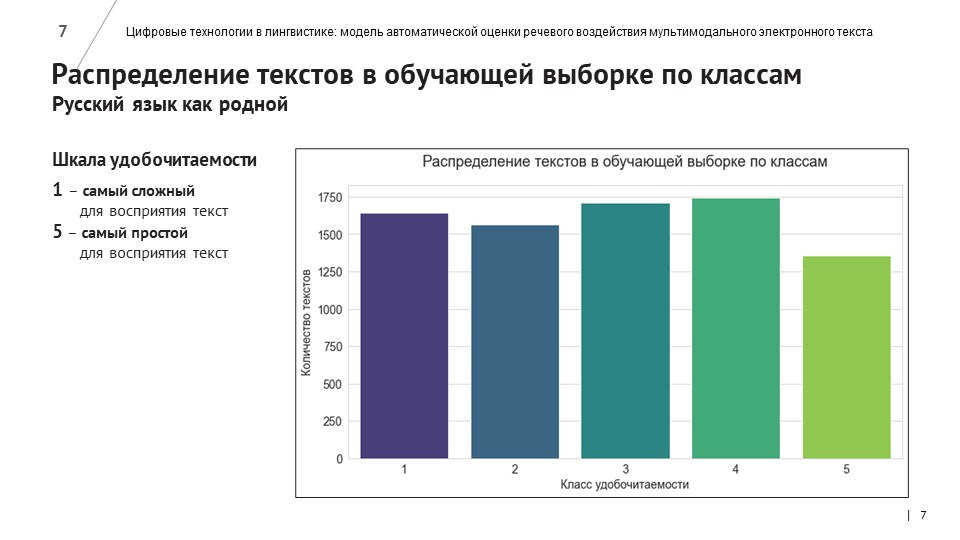
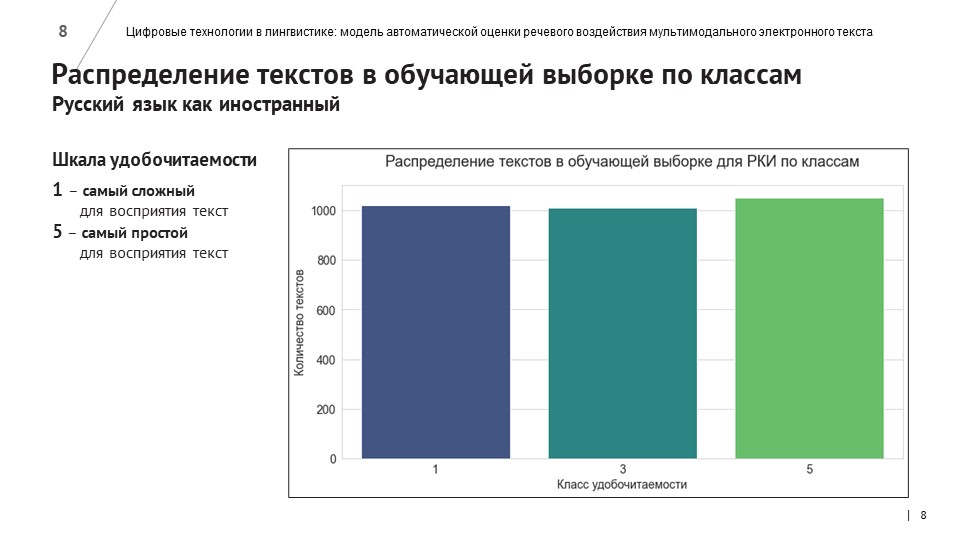
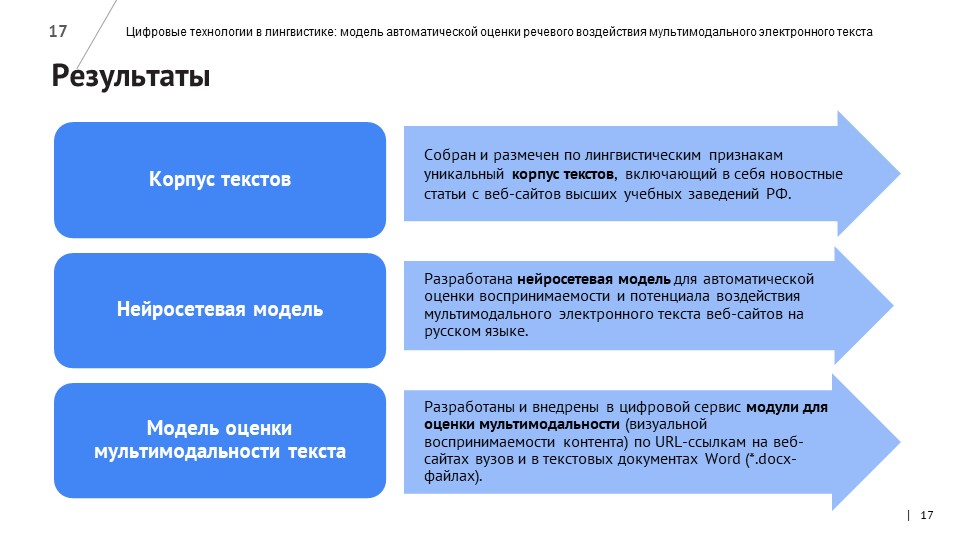
Разработчики написали программы для автоматического сбора новостных текстов с сайтов вузов. 1026 новостных материалов, собранных с помощью парсинга, компьютерные лингвисты разметили по более чем 40 лингвистическим признакам, используя метрики морфологической, лексической и синтаксической сложности, связности и структурирования текста. 326 текстов были также размечены по методу экспертной оценки – с помощью опроса студентов и преподавателей СПбПУ и других российских вузов.
Для улучшения работы модели обучающую выборку расширили еще на 7600 текстов, взятых с научно-популярного ресурса N+1, посвященного новостям о научных достижениях, открытиях и исследованиях.
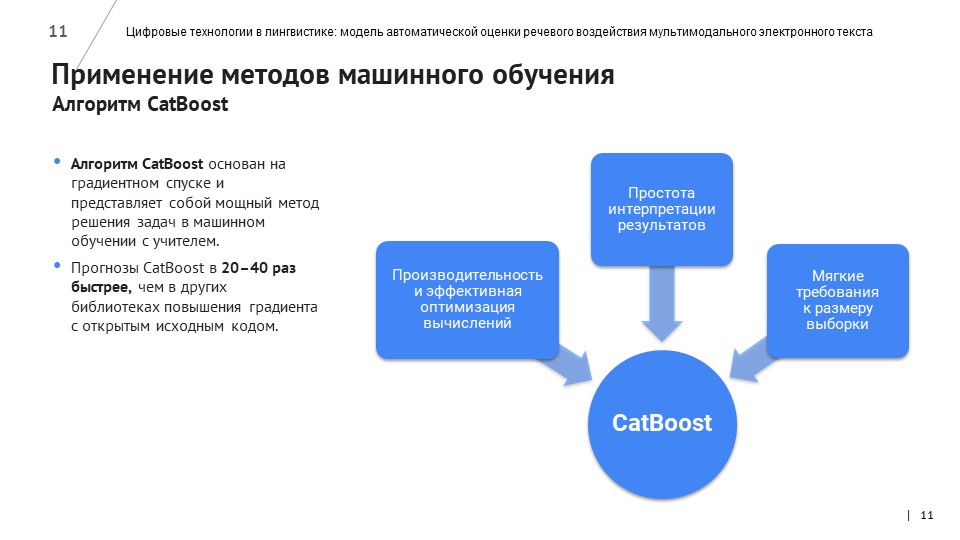
На основе созданной выборки разработчики обучили нейросеть с помощью алгоритма CatBoost.
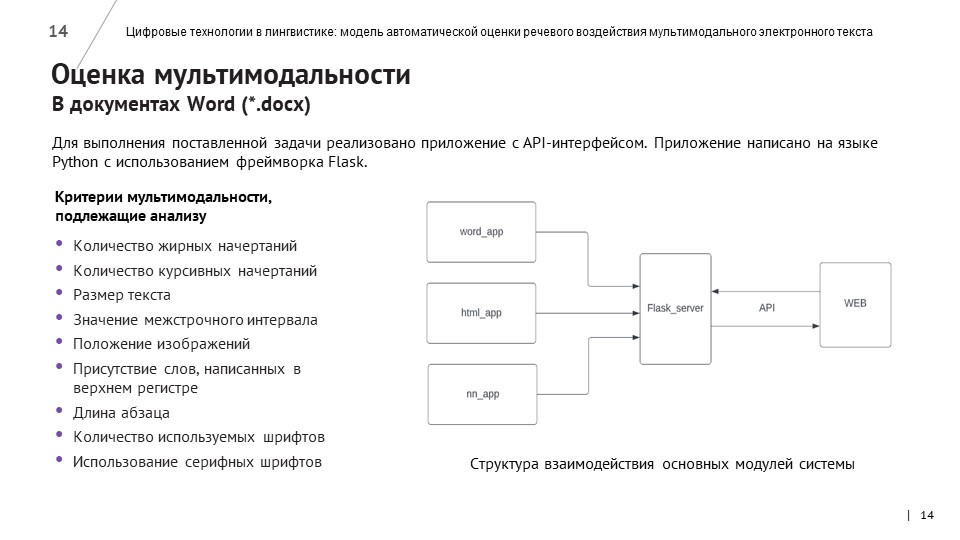
По похожему алгоритму собрали и данные о факторах, влияющих на визуальное восприятие информации на сайте. С помощью специализированного ПО были собраны данные об объектах сайта (изображения, видео, текстовые блоки) и их характеристиках, таких как ширина текстового блока, размер шрифта, величина межстрочного интервала, цвет шрифта и фона и так далее. Эти данные собирались из HTML- и CSS-файлов веб-страниц.
В ходе работы была создан удобный и доступный сервис для оценки читаемости и воспринимаемости мультимодальных электронных текстов, ориентированный на новостной, образовательный и научный контент официальных сайтов высших учебных заведений.







«Результаты нашей работы были направлены на улучшение восприятия текстов на веб-сайтах вузов. Сейчас мы работаем над увеличением доступных для анализа жанров и тематик для целенаправленной оценки текстов из других областей», – отметила спикер.
Работы по созданию сервиса, описанного в докладе, выполнялись в рамках стратегического проекта «Технополис «Политех» программы «Приоритет 2030».

